
Examining the Agile Cost of Change Curve
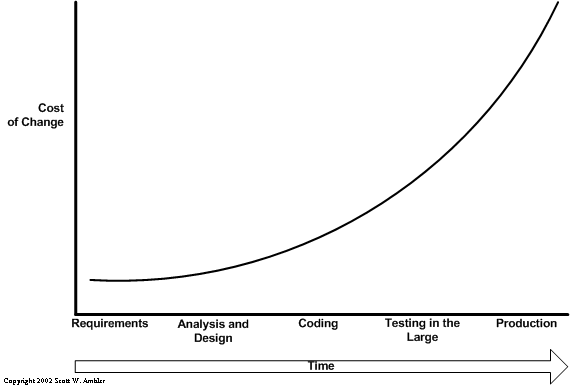 It is clear from Figure 1 that you want to test often and test early. By reducing the feedback loop, the time between creating something and validating it, you will clearly reduce the cost of change. In fact, Kent Beck argues that in eXtreme Programming (XP) the cost of change curve is flat, more along the lines of what is presented in Figure 2. Heresy you say! Not at all, Beck’s curve reflects the exact same fundamental rules that Figure 1 does. Once again, heresy you say! Not at all, the difference is that the feedback loop is dramatically reduced in XP. One way that you do so is to take a test-driven design (TDD) approach ( Beck 2003; Astels 2003). With a TDD approach the feedback loop is effectively reduced to minutes – instead of the days, weeks, or even months which is typical in serial processes – and as a result there isn’t on opportunity for the cost of change to get out of hand.Figure 2. Kent Beck’s cost of change curve.
It is clear from Figure 1 that you want to test often and test early. By reducing the feedback loop, the time between creating something and validating it, you will clearly reduce the cost of change. In fact, Kent Beck argues that in eXtreme Programming (XP) the cost of change curve is flat, more along the lines of what is presented in Figure 2. Heresy you say! Not at all, Beck’s curve reflects the exact same fundamental rules that Figure 1 does. Once again, heresy you say! Not at all, the difference is that the feedback loop is dramatically reduced in XP. One way that you do so is to take a test-driven design (TDD) approach ( Beck 2003; Astels 2003). With a TDD approach the feedback loop is effectively reduced to minutes – instead of the days, weeks, or even months which is typical in serial processes – and as a result there isn’t on opportunity for the cost of change to get out of hand.Figure 2. Kent Beck’s cost of change curve.
Although many people have questioned Beck’s claim, which was based on his own anecdotal evidence and initially presented as a metaphor to help people to rethink the things that they have believed for years. Frankly all he’s done IMHO is found a way to do what software engineering has recommended for a long time now, to test as early as possible – testing first is about as early are you’re going to get. To be fair, there’s more to this than simply TDD. With XP you reduce the feedback loop through pair programming as well as by working closely with their customers (stakeholders). One advantage of working closely with stakeholders is that they are available to explain their requirements to you, increasing the chance that you don’t misunderstand them, and you can show them your work to get feedback from them which enables you to quickly determine if you’ve built the right thing. The cost of change is also reduced by an explicit focus on writing high-quality code and by keeping it good through refactoring, a technique where you improve the design of your code without adding functionality to it. By traveling light, in other words by retaining the minimum amount of artifacts required to support the initiative, there is less to update when a change does occur.
|
|
|
Fundamentally, as Figure 3 shows, the reason why the agile cost of change curve has flattened is because we follow techniques which reduce the feedback cycle. Agile techniques, shown in green, have short feedback cycles and therefore are at the flat end of the curve. Traditional techniques, shown in red, have longer feedback cycles and therefore are at the higher-cost end of the curve.
Figure 3. Comparing the feedback cycle of various development techniques.

Figure 4 presents a cost of change curve that I think you can safely expect for agile software development. As you can see the curve doesn’t completely flatten but in fact rises gently over time. There are several reasons for this:
- You travel heavier over time. Minimally your business code and your test code bases will grow over time, increasing the chance that any change that does occur will touch more things later in the initiative.
- Non-code artifacts aren’t as flexible as code. Not only will your code base increase over time, so will your non-code base. There will be documents such as user manuals, operations manuals, and system overview documents that you will need to update. There are models, perhaps a requirements or architectural model, that you’ll also need to update over time. Taking an Agile Modeling Driven Development (AMDD) approach will help to reduce the cost of this but will not fully eliminate it.
- Deployment issues may increase your costs. When it becomes expensive to release software, perhaps you choose to distribute CDs instead of releasing software electronically to shared servers, your cost of change increases because you begin to follow more conservative, and more expensive, procedures (for example you may be more inclined to hold reviews).
- You may not be perfectly agile. Many agile software development teams find themselves in very non-agile environments and as a result are forced to follow procedures, such as additional paperwork or technical reviews, that increase their overall costs. These procedures not only increase the feedback loop they are very often not conducive to supporting change.
- We travel lighter. Agilists create high-value documentation, or in other words far less documentation than traditionalists do, and we don’t tolerate unnecessary bureaucracy. As a result we can act on changes quicker because we have less work to do — in other words, we maximize the amount of work not done.
Figure 4. A realistic cost of change curve for agile software development.

An important thing to understand about all three cost curves is that they represent the costs of change for a single, production release of software. Over time, as your system is released over and over you should expect your cost of change to rise over time. This is due to the fact that as the system grows you simply have more to code, models, documents, and so on to work with, increasing that chance that your team will need to work with artifacts that they haven’t touched for awhile. Although unfamiliarity will make it harder to work with and change an artifact, if you actively keep your artifacts of high quality they will be easier to change.
Another important concept concerning all three curves is that their scope is the development of major release of a system. Following the traditional approach some systems are released once and then bug fixes are applied over time via patches. Other times an incremental approach is taken where major releases are developed and deployed every year or two. With an agile approach an incremental approach is typically taken although the release timeframe is often shorter – for example releases once a quarter or once every six months aren’t uncommon, the important thing is that your release schedule reflects the needs of your users. Once the release of your system is in production the cost of change curve can change. Fixing errors in production is often expensive because the cost of change can become dominated by different issues. First, the costs to recover from a problem can be substantial if the error, which could very well be the result of a misunderstood requirement, corrupts a large amount of data. Or in the case of commercial software, or at least “customer facing” software that is used by the customers of your organization, the public humiliation of faulty software could be substantial (customers no longer trust you for example). Second, the cost to redeploy your system, as noted above, can be very large in some situations. Third, your strategy for dealing with errors affects the costs. If you decide to simply treat the change as a new requirement for a future release of the system, then the cost of change curve remains the same because you’re now within the scope of a new release. However, some production defects need to be addressed right away, forcing you to do an interim patch, which can clearly be expensive. When you include the cost of interim patches into the curves my expectation is that Figure 1 will flatten out at the high level that it has reached and that both Figure 2 and Figure 3 with potentially have jumps in them depending on your situation.
What is the implication for modeling? Although it may not be possible to reduce the feedback loop for non-code artifacts so dramatically, it seems clear that it is worth your while to find techniques that allow you to validate your development artifacts as early as possible.
Note: Portions of this article has been excerpted from The Object Primer 3/e.