
Agile Legacy System Analysis and Integration Modeling
1. Legacy System Analysis: Identifying Interactions
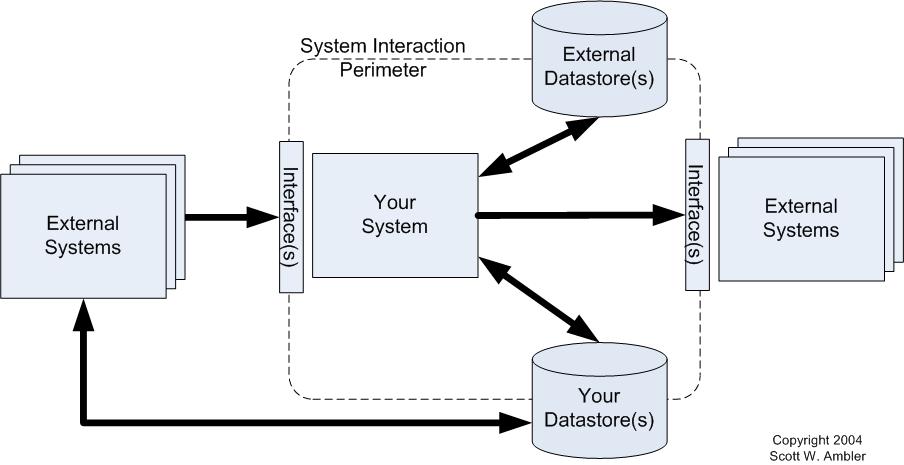
To identify the interactions your system has with others, you need to define the “interaction perimeter” of your system, as depicted in Figure 1. As you can see, there are five interaction possibilities:
- Reads from external data source(s). Your system may read data from external sources, such as files or databases. You will need to understand both the structure and semantics of the data.
- Updates to external data source(s). There are several implications. First, other systems may depend on the updates that your system makes, coupling them to yours. Second, your system may increase the traffic to the legacy data source and thereby affect the performance of other systems.
- External system interface(s). Your system may interact with other systems through provided systems interfaces, such as web services or an application programming interface (API). Your system could even invoke behaviour that other systems depend on, such as a batch job which updates an external database.
- Your data source(s). Other systems may read or write to data sources owned by your system. These systems depend on the data, or at least portions of the data.
- Your system interface(s). Other systems may interact with yours by accessing your data sources or via your own system interface(s).
Figure 1. The interaction perimeter of a system.
There are several legacy system analysis techniques to identify your system interaction perimeter:
- Read your system documentation. Your existing documentation, if any, should indicate how your system interfaces to other legacy assets and how they interact with it. Don’t assume that this documentation is complete and correct. Even though your organization may be meticulous in maintaining documentation it is possible that an interaction was introduced by another team that hasn’t been documented.
- Seek help from others. Enterprise architects, administrators, and operations staff are good people to involve because they have to work with multiple systems on a daily basis. Your operational administrators, particularly database and network administrators, may be your best bet as they’re responsible for managing the assets in production.
- Analyze the code. Without accurate documentation or access to knowledgeable people, your last resort may be to analyze the source code for the legacy system, including code which invokes your system. This effort is often referred to as software archaeology.
2. Legacy System Analysis: Identifying Legacy Assets
Once you’ve identified a potential interface which your system is involved with you need to identify the other systems/assets involved with that interface. Knowing the interface exists doesn’t automatically mean that you know which systems are using/supplying that interface. Ideally you shouldn’t need to know this information, but realistically you sometimes do. For example, your organization may have a collection of web services provided by a variety of systems which yours may reuse. You will need to know what services are available and what their signatures are, but you likely don’t need to know the underlying system(s) offering each service. However, you may be accessing a legacy database which is owned by another team. Minimally you’ll need to know the structure and semantics of the data which you’re accessing. However, you may also need to know which systems provide the data you’re using and the way in which they provide it (e.g. in batch refreshed daily at 2 am Greenwich mean time) to determine if you really want to use that data source. Ideally the contract model describing the database contains this sort of information, if not you may need to do the legacy analysis to obtain it. The thing to realize is that your system is part of the interaction perimeters of each of the external legacy assets, so you must look for the sort of interactions listed earlier from the point of view of those assets. It isn’t hard but it is usually tedious and time consuming.
3. Legacy System Analysis: Analyzing the Interaction(s)
Not only do you need to know which systems are coupled to yours, you need to understand how they’re coupled to your system. Your goal is to identify the way that these systems are coupled to your systems interaction perimeter. Issues to look for during your analysis include:
- Direction of the interaction. As noted previously, the direction of the interaction has different potential impacts.
- Information being exchanged. You need to identify which data, often down to the element level, is being accessed and how it is being used. This will help you to identify replacement data sources, if any, and how effective they are at covering the original need. For example an external system may access your database to obtain a complete list of products offered within the city of Atlanta. If all other data sources only relate products to the states in which they’re sold then the external system will no longer have the preciseness which it had before.
- Functionality being invoked. You need to identify the exact services (operations, procedures, functions, and so on) being invoked at the interaction perimeter.
- Frequency and volume. The frequency and the volume of the interaction are important pieces will indicate the load which you will put on the new sources for those interactions — they may not be able to handle the additional stress without infrastructure upgrades. Or, in the case of removing load the new sources may be over-powered, motivating your operations engineers to reconfigure the hardware and/or network resources for those systems and to divert them where they are needed more.
This is not always as straightforward as it might appear. While you may be able to readily identify the systems that feed data directly to your system, other interactions can be more subtle. You must track down systems (or users) that take an occasional data extract from your system (perhaps for a quarterly report), the ones that send an infrequent data feed, all systems that invoke functionality from your system (and vice versa), and all links to your system, even if it’s just a URL from a web page.
|
Another problem is the architecture impedance mismatch between systems. Each system is built based on its own set of architectural requirements. For example each system will have made a decision regarding timeliness: one database is updated weekly whereas another is updated daily. One system may be built to validate data in the application source code whereas another does it in the database. It is quite common for systems to be architected with the assumption that they will be the primary controller of the interactions, yet this clearly can’t be the case once they’re integrated. The implication is that the systems which perform essentially the same services which your system does may do so in an incompatible manner and therefore they can’t be considered as potential replacement sources.
3.1 Analyzing Legacy Data Sources
Data analysis is usually the most difficult part of analyzing system interaction. The data structures of your system and the system(s) your interfaces to will often be different, the database vendors can vary, the types of data sources (for example, relational databases versus XML Files versus IMS) will vary, and worse yet, the informational semantics are also likely to be different. For example, consider an ice cream company. One database maintains a flavours table, which contains rows for chocolate, strawberry, and vanilla. The replacement data source contains a table with the exact same layout, which maintains the flavours mocha fudge, ultimate chocolate, double chocolate, wild strawberry, winter strawberry, French vanilla, and old-fashioned vanilla. The new table arguably supports chocolate, strawberry, and vanilla, yet there is clearly a semantics problem which may be very difficult to overcome. Table 1 summarizes common legacy data challenges that you may encounter.
Table 1. Legacy data challenges.
| Challenge | Description |
| Data quality problems | There is a wide range of data quality issues. This includes: a column or table that is used for more than one purpose, missing or inconsistent data, incorrect formatting of data, multiple sources for the same data, important entities or relationships which are stored as text fields, data values that stray from their field descriptions and business rules, several key strategies for the same type of entity, different data types for similar columns, and varying default values. This list is nowhere near complete, but it should give you a feeling for the challenges which you will face. |
| Design problems | For example, data access may not be well encapsulated, or the encapsulation strategies may be difficult to use. |
| Architecture problems | Architecture problems are also serious issues across many legacy assets. Common data-oriented problems include applications that are responsible for data cleansing (instead of the database) and varying data timeliness. |
Luckily, there is a wealth of material available about how to refactor databases safely. However, many data professionals are still convinced that database refactoring is very difficult, if not impossible. Some will not even entertain the idea until they are shown a book such as Refactoring Databases, which describes in detail how to refactor an existing production database in an enterprise setting.
3.2 Analyzing Legacy Code
Code analysis is also a significant challenge, as Table 2 overviews. The legacy assets may:
- Be written in languages which your team is not familiar with.
- Not follow a consistent set of coding standards.
- Be difficult to understand.
- Not having up-to-date source code available (or it may not be clear which version to use).
Table 2. Legacy code challenges.
| Challenge | Description |
| Code quality problems | Similarly, you are likely to find problems in legacy code, such as inconsistent naming conventions, inconsistent or missing internal documentation, inconsistent operation semantics and/or signatures, highly coupled and brittle code, low cohesion operations which do several unrelated things, and code that is simply difficult to read. |
| Design problems | Applications may be poorly layered, with the user interface directly accessing the database, for example. An asset may be of high quality, but its original design goals may be at odds with current needs; for example, it may be a batch system, whereas you need real-time access. |
| Architecture problems | Architecture problems are also serious issues across many legacy assets. Common problems include: incompatible or difficult to integrate (often proprietary) platforms, fragmented and/or redundant data sources, inflexible architectures which are difficult to change, a lack of event notification, making it difficult to support real-time integration, and insufficient security. |
Luckily, there is a wide range of source code analysis tools available to you, as well as software modelling tools which are able to visualize your code. Code analysis is still hard even when you have good tools, but the tools definitely help.
4. Keeping Legacy System Analysis Agile
My advice is straightforward:
- Keep it simple. Contract models are agile documents which are just barely good enough , they don’t need to be perfect.
- Work in an evolutionary manner. You don’t need to develop all of the documentation for all of the system interactions up front. Instead, you can work iteratively, fleshing out the contract model(s) a bit at a time. You should also work incrementally, creating the contract model(s) and then, in turn, the actual integration code as you need them.
- Work closely with the legacy system owners. You need to work collaboratively and cooperatively with the legacy system owners if you are to succeed. Fundamentally, they own the system which you need to access; they can easily prevent you from doing so. Furthermore, they are the experts, they are the ones who should be actively involved with the legacy analysis efforts. This is yet another example of active stakeholder participation, where the stakeholders are the owners of the legacy asset(s).
- Consider look-ahead modeling. A good reason to do some look-ahead modeling is to ensure that a development team has sufficient information about an existing legacy asset which they need to integrate with.
- Don’t get hung up on the “one truth”. Many teams go astray when the data professionals involved with them focus too heavily on the one truth above all else.